




















Today, digital life depends on wireless communications. As per a study by Statista, 50 billion IoT devices will be in use by 2030. To cater to the requirement, there would be a constant increase in the number of enterprise-grade and consumer-grade network devices as the networks need to support more traffic and data than ever. An increase in the number of connections would result in an additional potential point of data. The data generated through the network devices would be in Petabytes to Zettabytes and so it would not be a wise decision to lose the data when the world is banking on it to drive different business objectives. Data is a gold mine for the majority of organizations because of the potential it represents
The increasing amount of data includes transmission and receiving traffic usage, connected clients, traffic used by connected clients, browsing history, alarms and notifications, configuration data, reports, client’s roaming history, and many other details. The variety, magnitude, and momentum of data from billions of devices is enormous but the networking companies are not able to gather and analyze the data to better understand customer and business requirements. This is because the old systems are no longer able to support the need and companies are unable to gain a competitive edge by leveraging massive data. But with the right architecture and implementation of Data Lake, companies can take full advantage of critical insights and recommendations
Table of Contents
Data Lake, Analytics and Beyond
Currently, a varied amount of data from access points, switches, routers, NAS, and other network devices are stored in different databases, data warehouses, and other storage systems. There arises a need to centralize the repository that allows ingesting, storing, discovering, analyze and visualizing all types of data. A centralized data repository that is capable of storing structured (SSID, device logs, bytes transferred, POS, CRM, databases, etc.) data, semi-structured data as well as unstructured, non-tabular raw data in its native format (like social media feeds, videos, images, enterprise systems, emails, blog content and more).
Data Lake is an ideal approach to harness the power of Big Data as it can be used to consolidate all of a network data in a single location, where it can be saved “as is,” without the need to impose a schema on it upfront. Companies can benefit from data lake’s incredible power by pulling out intelligent insights within seconds, without having to worry about infrastructure requirements by implementing advanced analytics.
By implementing data lake, networking companies can get numerous advantages as compared to the traditional data warehouses. Some of the key benefits include:
- Analytics: On-demand analytics can be performed by simplifying big data and unlocking the full potential of data lake implementation
- Scalability: In terms of the variety of data sources handled, scalability ensures to accommodate the growing amount of data in its native format without the immediate requirement of analyzing it.
- Data Availability: Availability and accessibility of data to different teams at any instance enabling different hierarchies in the process of decision making
- Data Authenticity: Allows to store data in different formats, retaining data authenticity
- Flexibility: Transforming data now and using it later can be a costly affair, organizations have the flexibility to transform data anytime in the future whenever needed.
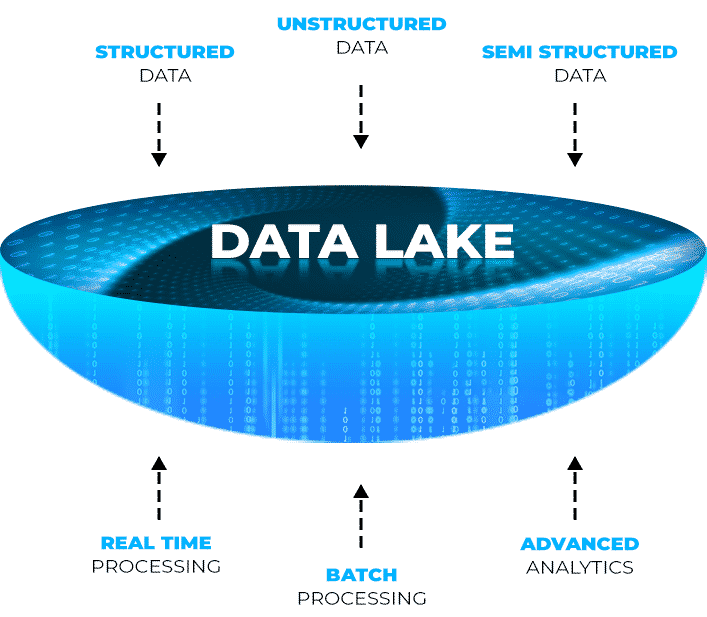
Data Lake solution can be implemented in an existing NMS solution and It enables companies to take advantage of the data for a wide variety of use cases that can be performed even without lifting or shifting the data when new data from network devices stream in
Listed below few of the use cases that can help companies take advantage of critical insights and recommendations:
- Network performance
- Network troubleshooting & optimization
- Network analysis based on
- Time
- Location
- Health monitoring of network devices
- Segmentation based targeting
- Micro targeted marketing
- Social network feeds
- Predictive analysis and many others
How VVDN can help OEMs?
VVDN Technologies is at par with its expertise and experience in implementing a secure, scalable, and governed enterprise data lake solution. We work hand in hand with companies from defining the use cases, designing and assessing the architecture design, implementing end-to-end data lake solutions from data ingestion, data storage, data preparation, data discovery to data visualization. The solution can be customized as per specific business requirements.
At VVDN, we bring together deep expertise and experience in various data management and analytics technologies such as Hadoop, Cassandra, S3, Azure Redis, Kafka, Elasticsearch, Apache Spark, AWS Lake formation, Spark engine, Amazon Athena, Azure data bricks, and many others. Having well versed with the latest tools and technologies, the solution can be deployed on-prem, AWS cloud, or Azure cloud as per specific business requirements. Our data lake services enable our clients to take advantage of the data lake solution and provide the best-in-class user experience.
Click here to know more about VVDN’s Data Lake Services.















